Автор: Денис Аветисян
Новый подход с использованием диффузионных моделей позволяет создавать плавные переходы и расширения аудио, открывая новые возможности для саунд-дизайнеров.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"
Исследование посвящено методам генерации и морфинга звука на основе диффузионных трансформеров и управления с помощью аудио-подсказок.
Расширение и плавное соединение звуковых фрагментов часто требует трудоемкой ручной работы в задачах звукового дизайна. В данной работе, посвященной теме ‘Generative Audio Extension and Morphing’, предлагается новый метод, использующий диффузионные трансформаторы и оригинальную технику управления генерацией, позволяющую создавать высококачественные и бесшовные расширения и морфинг аудио. Эксперименты демонстрируют возможность как продолжения существующих звуков, так и их плавного перехода друг в друга, при этом полученные результаты подтверждаются как объективными метриками (Fréchet Audio Distance), так и субъективной оценкой слушателей. Не откроет ли это путь к новым, более гибким и выразительным инструментам для звукорежиссеров, позволяющим им сосредоточиться на творческом процессе?
Преодолевая Границы Традиционного Звукового Синтеза
Традиционные методы продолжения аудиозаписей, такие как простое объединение фрагментов или сопоставление шумов с помощью свертки, часто сталкиваются с трудностями при создании бесшовных и реалистичных переходов. Эти подходы, хотя и позволяют в некоторой степени продлить звучание, зачастую приводят к заметным артефактам — щелчкам, разрывам или неестественным изменениям тембра. Проблема заключается в том, что они не учитывают сложные временные зависимости и акустические характеристики исходного сигнала, что делает продолжение звука неорганичным и неестественным для человеческого слуха. В результате, даже небольшие дефекты могут существенно снизить качество звука и разрушить иллюзию непрерывности, ограничивая возможности применения этих методов в задачах, требующих высокого уровня реализма и плавности.
Существующие методы расширения аудио, такие как простое объединение или сопоставление шумов, зачастую не способны генерировать сложные и контекстуально уместные звуки. Это ограничивает их применение в областях, требующих высокой степени реализма и гибкости, например, в творческом редактировании аудио или создании динамических звуковых ландшафтов. Вместо того, чтобы органично продолжать существующий звук, эти подходы часто приводят к заметным артефактам и неестественным переходам, что препятствует созданию убедительных и захватывающих звуковых опытов. Для реализации действительно плавных и контекстуально-обоснованных расширений необходимы более сложные алгоритмы, способные учитывать нюансы исходного звука и генерировать соответствующие продолжения.
Диффузионные Трансформеры: Новая Архитектура для Создания Звука
Архитектура Diffusion Transformer базируется на принципах диффузионных моделей, которые генерируют сложные аудиозаписи путем обратного процесса постепенного добавления шума. В основе лежит концепция последовательного удаления гауссовского шума из случайного сигнала, начиная с полностью шумового состояния, до получения когерентного аудиосигнала. Этот процесс моделируется как марковский процесс, где каждый шаг уменьшает уровень шума, приближая сигнал к целевому аудио. Для достижения высокого качества генерации используются методы обучения, направленные на точное моделирование обратного диффузионного процесса и эффективное восстановление исходного сигнала из зашумленного представления.
В архитектуре Diffusion Transformer ключевым элементом является использование сети-трансформера внутри процесса диффузии. Это позволяет модели улавливать долгосрочные зависимости в аудиосигнале, что критически важно для генерации когерентных и контекстуально осмысленных звуков. В отличие от традиционных подходов, трансформер способен эффективно обрабатывать взаимосвязи между отдаленными фрагментами аудио, обеспечивая более реалистичную и связную звуковую структуру. Способность модели учитывать широкий контекст позволяет ей генерировать звуки, которые не просто соответствуют заданным параметрам, но и логически согласованы с предыдущими и последующими звуковыми событиями.
В архитектуре Diffusion Transformer применение функции активации SwiGLU (Switched GLU) внутри трансформаторной сети способствует повышению производительности и стабильности процесса генерации аудио. SwiGLU, являясь вариантом GLU (Gated Linear Unit), использует механизм переключения (switching) для динамического выбора между различными линейными преобразованиями входных данных. Это позволяет модели более эффективно обрабатывать и передавать информацию, избегая проблем, связанных с затуханием или взрывом градиентов при обучении, особенно в глубоких сетях. Внедрение SwiGLU приводит к улучшению сходимости обучения и повышению качества генерируемого аудио за счет более эффективного использования параметров и снижения вычислительной сложности по сравнению с традиционными функциями активации, такими как ReLU или tanh.
Кодирование Звуковой Реальности: Латентные Пространства и Управление
Для представления аудиоданных в сжатом и информативном виде используется вариационный автоэнкодер (VAE). VAE преобразует входной аудиосигнал в латентное пространство меньшей размерности, сохраняя при этом существенные характеристики звука. Этот процесс включает в себя кодирование аудио в вероятностное распределение в латентном пространстве, что позволяет не только уменьшить объем данных, но и обеспечить возможность генерации новых, похожих аудиосигналов путем выборки из этого распределения. Такое представление позволяет эффективно обрабатывать и манипулировать звуком, а также использовать его для различных задач, включая синтез, редактирование и анализ.
Для сохранения пространственной информации в процессе кодирования аудио используются методы стереокодирования. Данные методы позволяют представить звуковое поле в виде компактного латентного пространства, сохраняя при этом информацию о взаимном расположении источников звука и их влиянии на восприятие. Это достигается за счет кодирования левого и правого каналов аудиосигнала в отдельные векторы латентного пространства, либо путем использования специализированных алгоритмов, учитывающих разницу во времени прибытия звука к левому и правому уху. В результате, при декодировании, обеспечивается воссоздание реалистичной звуковой сцены с ощущением объема и позиционирования звуковых объектов, что существенно повышает степень погружения и реалистичность звукового опыта.
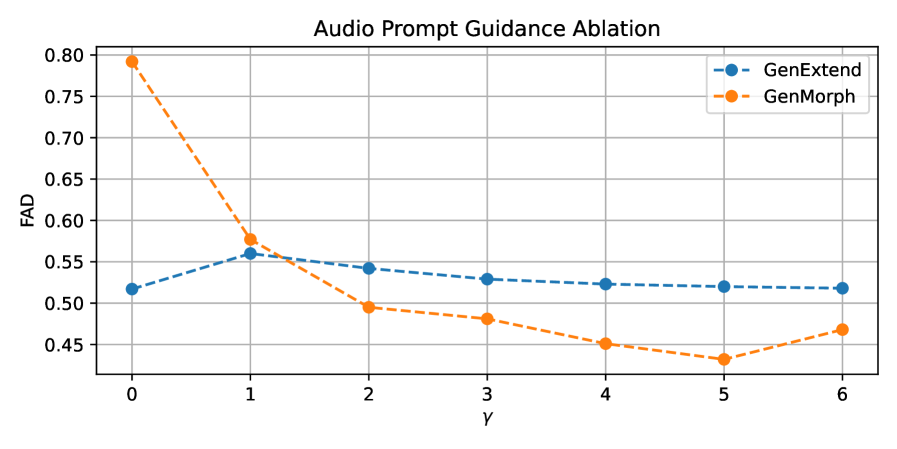
Для управления процессом генерации звука и обеспечения заданных характеристик используется метод Audio Prompt Guidance, представляющий собой расширение подхода Classifier-Free Guidance. В основе метода лежит масштабирование предсказаний модели диффузии в зависимости от “подсказки” (audio prompt) и отсутствия подсказки. Это позволяет модели “смещаться” в сторону желаемого звукового профиля, определяемого аудио-подсказкой, без необходимости обучения отдельного классификатора. Увеличение веса подсказки приводит к более сильному влиянию желаемого звука, а уменьшение — к большей свободе генерации. Эффективность Audio Prompt Guidance обусловлена способностью модели диффузии учитывать и комбинировать информацию из аудио-подсказки с имеющимся латентным пространством, обеспечивая точное и контролируемое формирование звука.
Подтверждение Реализма: Валидация и Снижение Артефактов
Для оценки качества сгенерированного звука применялась метрика Fréchet Audio Distance (FAD), позволяющая количественно оценить степень сходства между распределением сгенерированных и реальных звуковых сигналов. FAD измеряет расстояние между этими распределениями в многомерном пространстве признаков, эффективно улавливая различия в структуре и характеристиках звука. Низкое значение FAD указывает на высокую степень реалистичности сгенерированного звука и его соответствие реальным звуковым данным, что свидетельствует о способности модели создавать убедительные и правдоподобные звуковые ландшафты. Этот подход обеспечивает объективную оценку качества звука, дополняя субъективные оценки экспертов в области звукового дизайна.
Модель демонстрирует высокую степень реалистичности генерируемого звука, что подтверждается результатами оценки с использованием метрики Fréchet Audio Distance (FAD). В ходе экспериментов для метода Generative Extension был достигнут показатель FAD в 0.426, а для Generative Morphing — 0.432. Эти значения свидетельствуют о минимальном различии между распределениями сгенерированных и реальных аудиозаписей, что указывает на способность модели создавать звуки, практически неотличимые от естественных. Низкий показатель FAD подтверждает эффективность предложенного подхода к генерации звука и его потенциал для широкого спектра применений, требующих высокого качества и реализма аудио.
Для снижения вероятности генерации нежелательных или нереалистичных звуков, так называемых “галлюцинаций”, модель прошла дополнительную тонкую настройку с использованием специального набора данных “Noise Floor Dataset”. Этот набор содержит аудиозаписи, характеризующиеся низким уровнем фонового шума, что позволило модели лучше различать полезный сигнал от артефактов. В результате данной процедуры значительно улучшилось общее качество генерируемого звука и повысился уровень его реалистичности, поскольку модель научилась более точно воспроизводить звуковые ландшафты, избегая появления неестественных или отвлекающих элементов.
Для оценки субъективного качества сгенерированного звука, группа опытных специалистов в области звукового дизайна провела оценку с использованием шкалы Mean Opinion Score (MOS). Результаты показали, что сгенерированные аудиофрагменты получили средний балл от 3.5 до 3.8 по критериям плавности, согласованности и общего качества звучания. Этот диапазон оценок свидетельствует о высокой степени соответствия сгенерированного звука восприятию человека и подтверждает его реалистичность, что является важным показателем успешности модели в области генерации аудиоконтента.
Исследование демонстрирует элегантность подхода к созданию аудио, где простота архитектуры Diffusion Transformers позволяет добиться бесшовных переходов и расширений. Авторы, подобно архитекторам, тщательно продумывают каждую деталь системы, понимая, что изменение одной части неминуемо влияет на всю структуру. Тим Бернерс-Ли однажды сказал: «Интернет — это для всех». Данная работа, используя методику Audio Prompt Guidance, предоставляет инструменты для расширения возможностей звукорежиссеров, делая процесс создания звука более интуитивным и доступным, что соответствует принципам открытости и универсальности, заложенным в основу сети. Подобно тому, как невозможно пересадить сердце, не понимая кровотока, данное исследование демонстрирует важность целостного подхода к архитектуре аудиосистем.
Куда Дальше?
Представленная работа, безусловно, демонстрирует элегантность подхода к расширению и трансформации аудио, однако не стоит забывать, что любая абстракция имеет свою цену. Оптимизация лишь отдельных аспектов генерации, например, скорости или «качественности» в рамках метрики Fréchet Audio Distance, может привести к упущению более тонких, субъективных характеристик звука, важных для опытного звукорежиссера. По сути, мы оптимизируем не то, что нужно, а то, что измеримо.
Настоящим вызовом видится не столько создание «бесшовных» переходов, сколько развитие методов, позволяющих контролировать структуру этих переходов. Простота масштабируется, изощрённость — нет; использование latent masking, безусловно, полезно, но требует дальнейшего изучения в контексте долгосрочной когерентности и предсказуемости. Хорошая архитектура незаметна, пока не ломается, и в данном случае «поломкой» будет являться нарушение логики звукового повествования.
В конечном итоге, истинный прогресс заключается не в увеличении числа параметров модели, а в понимании того, как эти параметры влияют на восприятие звука. Зависимости — настоящая цена свободы, и необходимо тщательно взвешивать преимущества гибкости и выразительности против неизбежных ограничений, накладываемых сложностью системы. Следующим шагом видится разработка методов, позволяющих «обучать» модель не только генерировать звук, но и «понимать» его.
Оригинал статьи: https://arxiv.org/pdf/2602.16790.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Oppo Find X9 Ultra ОБЗОР: большой аккумулятор, скоростная зарядка, чёткое изображение
- Неважно, на что вы фотографируете!
- Российский рынок: Рубль, Нефть и Корпоративные Истории – Что Ждет Инвесторов? (02.04.2026 23:32)
- Motorola Moto G34 ОБЗОР: большой аккумулятор, быстрый сенсор отпечатков, лёгкий
- IdeaPad Slim 3 15IRH10R ОБЗОР
- Canon EOS 80D
- Рост облигаций и геополитика: что ждет инвесторов в апреле? (08.04.2026 17:32)
- Российский рынок: умеренный рост на фоне увеличения нефтедобычи и роста зарплат (05.04.2026 21:32)
- Infinix Note 40 Pro+ выставлен на обзор
- Рекомендации нового поколения: объединяя визуальное и текстовое
2026-02-22 23:58