Автор: Денис Аветисян
Новое исследование показывает, что для эффективной декодировки нейронных сигналов необходимо учитывать разницу в способах обработки визуальной информации человеком и искусственным интеллектом.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"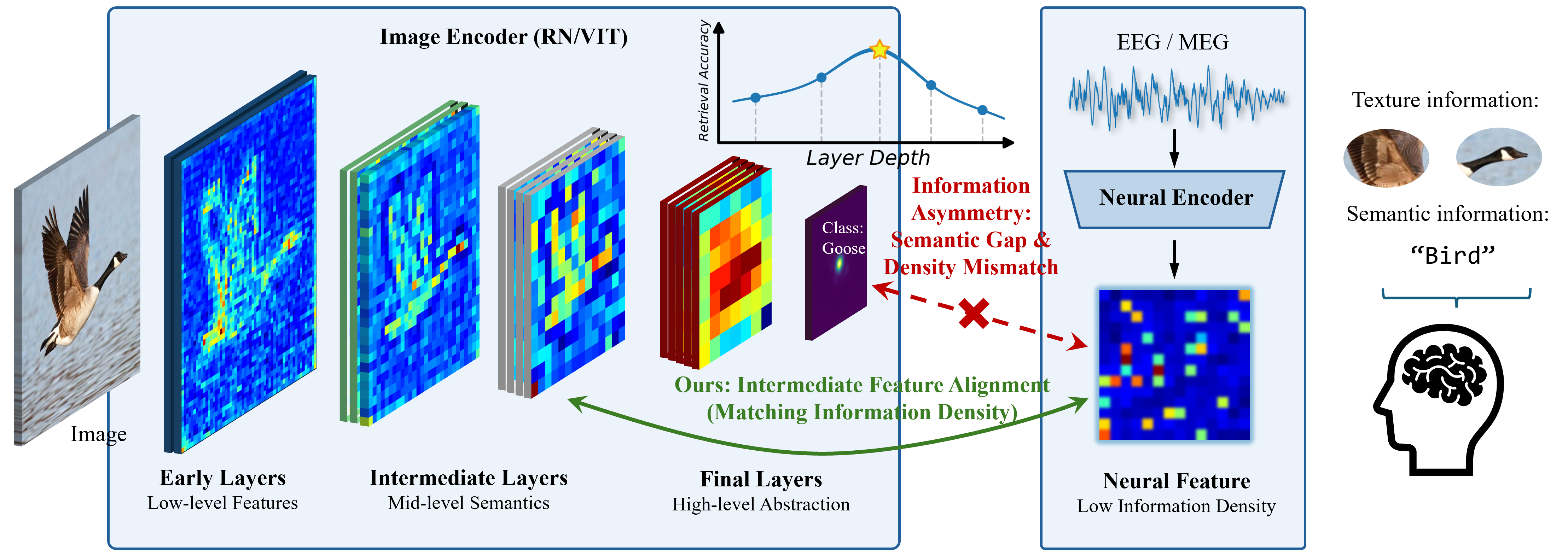
Согласование нейронных сигналов с промежуточными слоями глубоких моделей машинного зрения значительно повышает точность декодирования, решая проблему несоответствия гранулярности.
Существующие подходы к декодированию нейронной активности часто упускают из виду принципиальные различия в способах обработки визуальной информации человеком и машиной. В работе «Deep Models, Shallow Alignment: Uncovering the Granularity Mismatch in Neural Decoding» предложена стратегия «Поверхностного Выравнивания», которая сопоставляет нейронные сигналы с промежуточными представлениями визуальных энкодеров, а не с их конечными результатами. Это позволяет добиться значительного улучшения точности декодирования, выявляя и учитывая расхождение в уровне детализации между нейронными и машинными системами. Возможно ли дальнейшее повышение эффективности декодирования за счет адаптации стратегии выравнивания к различным типам нейронных данных и архитектурам визуальных моделей?
Раскрывая Тайны Сознания: Ключ к Нейронной Визуальной Декодировке
Восстановление визуальных переживаний на основе активности мозга, известное как нейронная визуальная декодировка, представляет собой перспективный подход к пониманию механизмов восприятия и познания. Эта область исследований стремится «прочитать» по нейронным сигналам, что видит человек, открывая возможности для создания интерфейсов «мозг-компьютер» для помощи людям с нарушениями зрения или для восстановления утраченных воспоминаний. По сути, декодировка позволяет заглянуть внутрь сознания, чтобы понять, как мозг конструирует наше субъективное зрительное восприятие, и какие нейронные процессы лежат в основе формирования зрительных образов, что, в свою очередь, углубляет понимание когнитивных функций, связанных с вниманием, памятью и принятием решений.
Существует фундаментальное препятствие в области декодирования визуальной информации из активности мозга, связанное с несоответствием гранулярности представления данных. Современные модели компьютерного зрения, стремясь к обобщению и эффективности, часто создают чрезмерно абстрактные репрезентации изображений, теряя многоуровневую детализацию, присущую нейронным сигналам. В то время как мозг сохраняет информацию о визуальном мире на различных масштабах — от общих форм до мельчайших текстур — существующие алгоритмы машинного обучения склонны к упрощению, что затрудняет точное восстановление исходного визуального опыта. Это несоответствие между степенью детализации нейронных представлений и абстракциями, используемыми в моделях, является ключевой проблемой, ограничивающей возможности точного декодирования зрительных образов из активности мозга.
Современные модели компьютерного зрения, основанные на глубоком обучении, зачастую создают чрезмерно абстрактные представления визуальной информации. В отличие от этих моделей, нейронные сети мозга сохраняют детали на различных масштабах — от общих контуров до тонких текстур и цветовых нюансов. Эта разница в детализации, известная как несоответствие гранулярности, представляет собой серьезное препятствие для точной декодировки зрительных образов из мозговой активности. Попытки восстановить увиденное из нейронных сигналов оказываются затруднены, поскольку модели не способны уловить богатую многомасштабную информацию, закодированную в нейронах, что ограничивает их способность точно реконструировать визуальный опыт.
Визуальные Кодировщики и Поиск Гармонии
Современные кодировщики изображений, такие как ResNet, Vision Transformer, DINOv2 и InternViT, являются основой для извлечения визуальных признаков. Эти архитектуры, основанные на глубоком обучении, преобразуют входные изображения в векторные представления, которые затем используются в различных задачах компьютерного зрения. ResNet использует остаточные соединения для облегчения обучения глубоких сетей, Vision Transformer применяет механизм внимания, изначально разработанный для обработки естественного языка, к изображениям, DINOv2 использует самообучение с дистилляцией знаний для получения более устойчивых признаков, а InternViT оптимизирован для работы с изображениями высокого разрешения. Выбор конкретной архитектуры кодировщика существенно влияет на качество извлеченных признаков и, следовательно, на производительность всей системы.
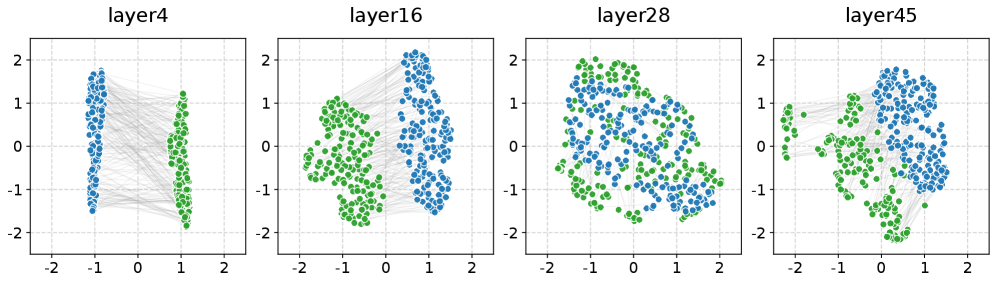
Успешное сопоставление визуальных признаков, извлеченных энкодерами, с нейронными сигналами требует тщательного анализа архитектуры используемого энкодера и конкретного слоя, с которым происходит выравнивание. Различные архитектуры энкодеров — от ResNet до Vision Transformer — по-разному представляют визуальную информацию, что влияет на эффективность сопоставления. Кроме того, выбор слоя для выравнивания критичен: более глубокие слои содержат абстрактные представления, которые могут не соответствовать детальным нейронным сигналам, в то время как ранние слои сохраняют больше структурной информации, но могут оказаться недостаточно информативными для точного сопоставления. Оптимальный выбор архитектуры и слоя зависит от конкретной нейрофизиологической задачи и характеристик измеряемых нейронных сигналов.
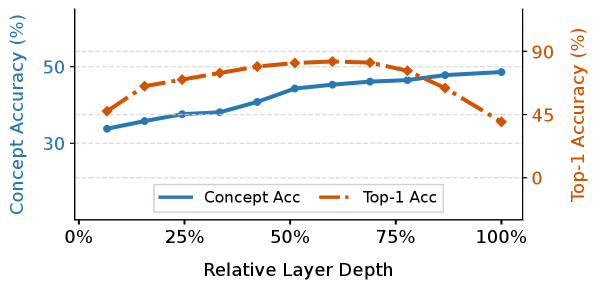
Прямое сопоставление признаков, извлеченных из глубоких слоев vision encoder, с нейронными сигналами часто усугубляет проблему несоответствия гранулярности — различия в уровне детализации представления информации. Это связано с тем, что глубокие слои, как правило, оперируют более абстрактными и высокоуровневыми признаками, которые могут быть слишком обобщенными для точного соответствия конкретным нейронным ответам. В связи с этим, исследования направлены на поиск решений в более ранних слоях архитектуры vision encoder, которые сохраняют большую структурную близость к исходному изображению и, следовательно, предоставляют более детальное и точное представление визуальной информации, лучше соответствующее нейронным сигналам.
Поверхностное Выравнивание: Ключ к Улучшенной Декодировке
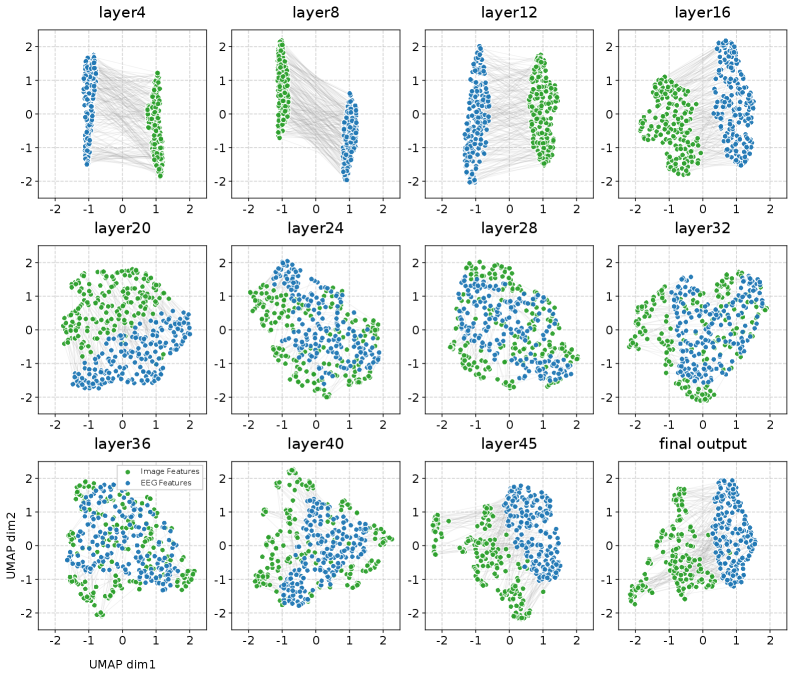
Механизм “Поверхностного Выравнивания” представляет собой новую структуру, предназначенную для сопоставления нейронных сигналов с “Промежуточными Слоями” кодировщиков зрения. Основная цель данного подхода — смягчение эффектов несоответствия гранулярности, возникающего при сравнении данных разной степени детализации. Сопоставление осуществляется не с финальным выходом кодировщика, а с промежуточными представлениями, что позволяет более эффективно учитывать и компенсировать различия в уровне абстракции между нейронными сигналами и визуальными признаками. Это позволяет добиться более точной интерпретации и декодирования нейронной активности, связанной с визуальным восприятием.
Для эффективного сопоставления и выравнивания нейронных сигналов и признаков, извлекаемых из энкодеров зрения, используется линейный семантический проектор. Этот проектор преобразует признаки из различных пространств в общее латентное пространство, где возможно прямое сравнение и вычисление расстояний между ними. Линейная проекция позволяет сохранить семантическую информацию, необходимую для установления соответствий, и упрощает процесс обучения, поскольку количество параметров остается относительно небольшим. В результате, нейронные и визуальные представления оказываются в едином пространстве, что облегчает поиск соответствий и повышает точность декодирования.
В рамках предложенного подхода, контрастное обучение используется для оптимизации соответствия между нейронными и визуальными представлениями. Метод максимизирует сходство (косинусное расстояние или другие метрики) между соответствующими нейронными и визуальными эмбеддингами, что позволяет системе более эффективно сопоставлять сигналы мозга с визуальными особенностями. Одновременно, контрастное обучение минимизирует сходство между несвязанными нейронными и визуальными эмбеддингами, что способствует повышению дискриминационной способности модели и предотвращает ложные срабатывания при декодировании. Это достигается путем формирования пар положительных (соответствующих) и отрицательных (несоответствующих) примеров и обучения модели отличать их друг от друга.
Подтверждение Эффективности Поверхностного Выравнивания на Крупномасштабных Данных
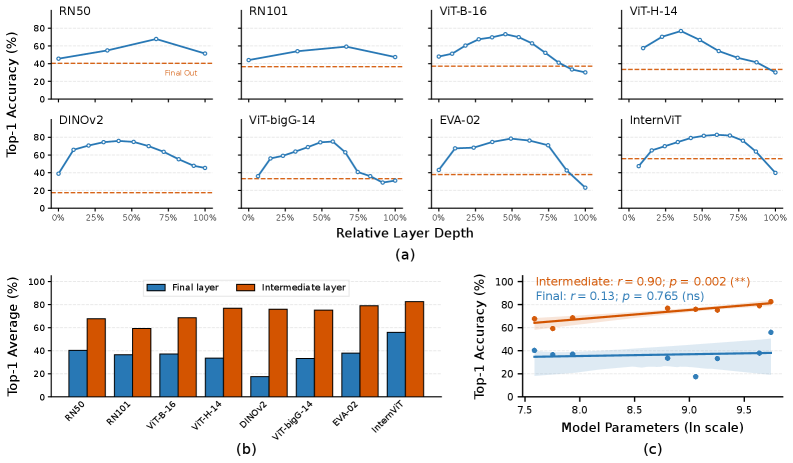
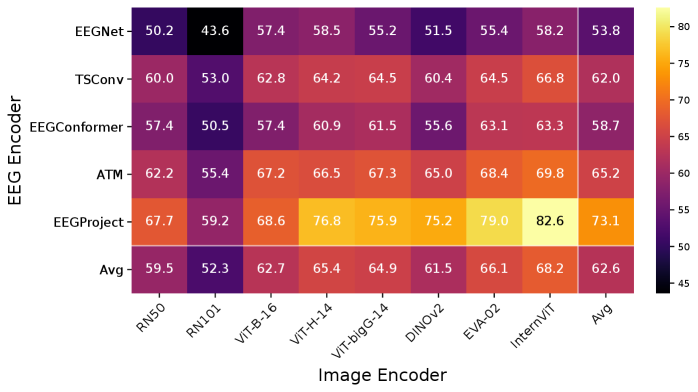
Оценка метода Shallow Alignment проводилась на двух крупных наборах данных — ‘THINGS-EEG’ и ‘THINGS-MEG’. Результаты показали, что предложенный подход демонстрирует превосходство над традиционными методами в задачах валидации. Сравнение производительности на этих наборах данных подтверждает эффективность Shallow Alignment в обработке и анализе данных электроэнцефалографии (ЭЭГ) и магнитоэнцефалографии (МЭГ) по сравнению с существующими алгоритмами.
На датасете THINGS-EEG предложенный фреймворк достиг показателя Top-1 точности в 82.6%. Этот результат является передовым для текущего состояния исследований в данной области. Оценка проводилась на основе классификации сигналов ЭЭГ, и достигнутая точность демонстрирует эффективность предложенного подхода к выравниванию признаков и классификации данных ЭЭГ. Достижение такого уровня точности указывает на способность фреймворка эффективно извлекать и классифицировать релевантные признаки из сложных данных ЭЭГ.
В ходе экспериментов было установлено, что смещение целевой точки для выравнивания (alignment) с финального слоя нейронной сети на оптимальный промежуточный слой, использующий DINOv2, привело к значительному улучшению метрики Top-1 accuracy — на 58.4%. Это свидетельствует о том, что промежуточные представления, полученные с использованием DINOv2, содержат более релевантную информацию для задачи классификации, чем выходные данные финального слоя, и, следовательно, их использование в качестве целевой точки для выравнивания повышает точность модели.
Для повышения производительности разработанной системы, в нее были интегрированы передовые методы обработки сигналов. В частности, использовались архитектуры ‘EEGNet’, ‘ATM’ и ‘TSConv’, специализирующиеся на извлечении признаков из данных ЭЭГ и МЭГ. Для снижения вычислительной сложности и повышения эффективности обучения, применялось понижение размерности с использованием алгоритма ‘UMAP’, что позволило сократить количество параметров и улучшить обобщающую способность модели без существенной потери информации.
Перспективы Развития: К Созданию Полной Системы «Чтения Мыслей»
Проведенная работа закладывает основу для создания более полной и надежной системы «Нейровизуальной Декодировки», способной реконструировать сложные зрительные переживания на основе активности мозга. В ходе исследования удалось продемонстрировать возможность восстановления базовых визуальных характеристик — формы, цвета и ориентации объектов — непосредственно из нейронных сигналов. Это представляет собой значительный шаг вперед по сравнению с предыдущими попытками, которые часто ограничивались простыми стимулами или требовали обширного обучения для каждого конкретного субъекта. Перспективные направления развития включают в себя расширение возможностей декодирования до более сложных и динамичных сцен, а также интеграцию с другими нейротехнологиями для создания систем, способных «читать» не только то, что видит человек, но и то, что он думает и чувствует.
В дальнейшем исследования будут сосредоточены на разработке более сложных методов выравнивания данных и интеграции контекстной информации для повышения точности декодирования. Ученые стремятся к созданию алгоритмов, способных учитывать индивидуальные особенности мозга и динамически изменяющиеся условия восприятия. Особое внимание уделяется учету предыдущего опыта и ожиданий, поскольку эти факторы существенно влияют на то, как мозг обрабатывает визуальную информацию. Совершенствование этих методов позволит не только точнее реконструировать визуальные образы из нейронной активности, но и существенно расширить возможности применения данной технологии в различных областях, включая нейрореабилитацию и создание интерфейсов «мозг-компьютер».
Развитие технологий нейронной декодировки визуальной информации открывает перспективы, выходящие далеко за рамки чистого научного интереса. Предполагается, что в будущем подобные системы смогут предоставить инструменты для восстановления коммуникации у людей с нарушениями речи или параличом, позволяя им выражать мысли напрямую через декодирование мозговой активности. Реабилитационный потенциал также огромен, поскольку декодирование зрительных образов может помочь в восстановлении функций мозга после травм или инсультов. Кроме того, ведутся исследования по использованию этих технологий для когнитивного усиления, например, для улучшения памяти или концентрации внимания, открывая новые возможности для обучения и развития человеческого потенциала.
Исследование демонстрирует, что несоответствие гранулярности между тем, как человек и машина обрабатывают визуальную информацию, является ключевым препятствием в нейродекодировании. Авторы статьи подчеркивают, что выравнивание нейронных сигналов с промежуточными слоями глубоких моделей зрения значительно улучшает производительность, позволяя преодолеть этот разрыв. Это согласуется с мыслями Дэвида Марра: «Понимание требует построения многоуровневой модели мира, где каждый уровень представляет собой различную степень абстракции». Действительно, использование промежуточных представлений в моделях позволяет приблизиться к иерархической структуре обработки информации, характерной для человеческого мозга, и добиться более точного декодирования нейронных сигналов. Утонченность этого подхода свидетельствует о глубоком понимании принципов когнитивной архитектуры.
Куда же дальше?
Представленные результаты, безусловно, указывают на необходимость переосмысления подходов к нейронной декодировке. Долгое время предполагалось, что наиболее эффективным является сопоставление нейронных сигналов с конечным результатом работы глубокой сети. Однако, как показывает данное исследование, эта аналогия груба и несовершенна. Наблюдаемое несоответствие гранулярности указывает на фундаментальную разницу в том, как человек и машина извлекают информацию из визуального мира. Очевидно, что простое «подгоняние» нейронных данных к выходным слоям — это, скорее, попытка замаскировать принципиальное непонимание, нежели истинное решение.
Будущие исследования должны быть направлены на более глубокое понимание промежуточных представлений в глубоких сетях и их соответствия нейронным механизмам обработки информации. Необходимо исследовать, какие именно слои и признаки наиболее тесно связаны с конкретными аспектами визуального восприятия. При этом, стоит учитывать, что визуальные трансформаторы — лишь один из возможных подходов, и другие архитектуры могут потребовать иных стратегий выравнивания.
Возможно, истинная элегантность кроется не в совершенствовании алгоритмов декодировки, а в разработке моделей, которые изначально проектируются с учетом нейронных принципов обработки информации. В конечном итоге, задача состоит не в том, чтобы заставить машину «понимать» нас, а в том, чтобы создать систему, которая по-настоящему отражает сложность и красоту человеческого восприятия.
Оригинал статьи: https://arxiv.org/pdf/2601.21948.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Acer Aspire 5 Spin 14 ОБЗОР
- Huawei nova 15 Max ОБЗОР
- Wiko Hi Enjoy 60s ОБЗОР: быстрый сенсор отпечатков, большой аккумулятор
- Российский рынок: от оттока наличных к смешанной динамике и ожиданиям ЦБ (07.05.2026 20:32)
- Oppo Find X9s Pro ОБЗОР: скоростная зарядка, современный дизайн, замедленная съёмка видео
- vivo iQOO Z10x ОБЗОР: яркий экран, удобный сенсор отпечатков, объёмный накопитель
- Российский рынок: дефляция, рубль и геополитика – обзор ключевых событий недели (06.05.2026 19:32)
- ВИ.РУ акции прогноз. Цена VSEH
- Как работает поляризационный фильтр
- Oppo A78 4G ОБЗОР: большой аккумулятор, скоростная зарядка, лёгкий
2026-01-30 18:58