Автор: Денис Аветисян
Новое исследование показывает, что современные модели компьютерного зрения способны рассуждать о том, как с объектами можно взаимодействовать, опираясь на понимание их формы и потенциальных действий.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"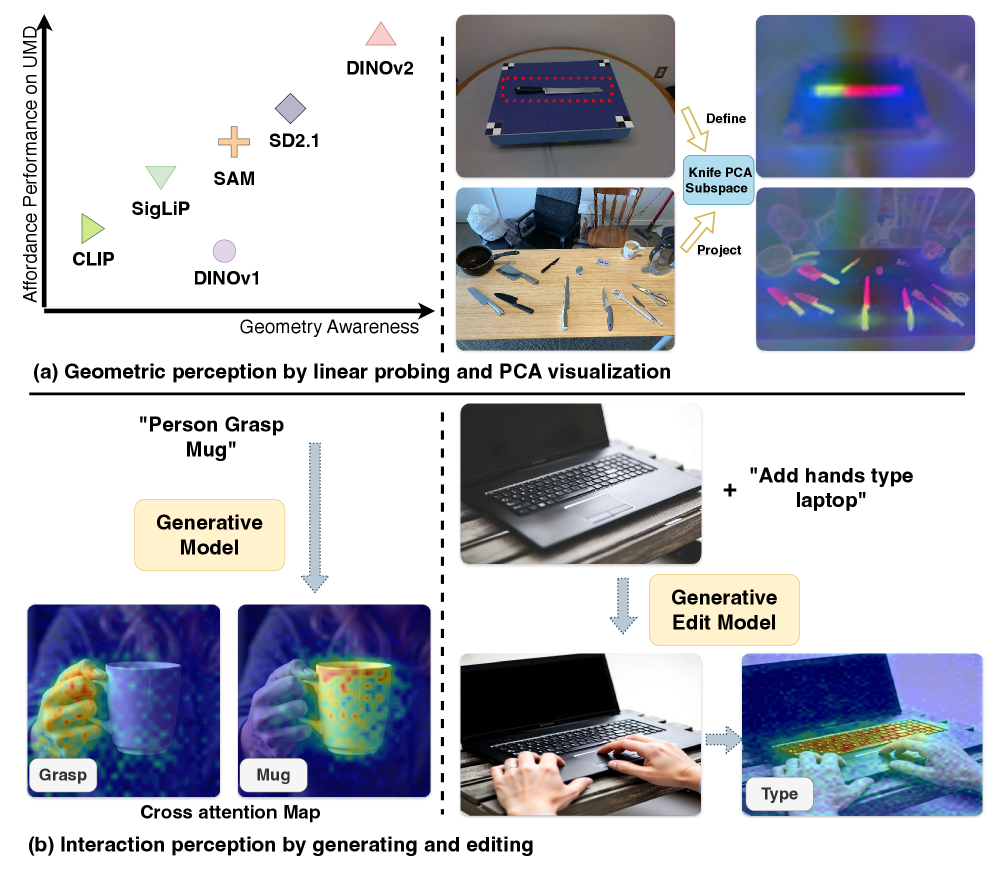
Анализ геометрических и интерактивных сигналов в визуальных фундаментальных моделях демонстрирует их способность к рассуждениям об affordance без дополнительного обучения.
Понимание визуальных возможностей взаимодействия с объектами остается сложной задачей для современных систем компьютерного зрения. В работе ‘Probing and Bridging Geometry-Interaction Cues for Affordance Reasoning in Vision Foundation Models’ авторы исследуют, как геометрическое восприятие объектов и понимание взаимодействия с ними влияют на способность моделей к рассуждениям об affordance. Показано, что существующие визуальные фундаменльные модели (VFM) неявно кодируют информацию о геометрии объектов и вероятных способах взаимодействия, и объединение этих сигналов позволяет достичь результатов, сопоставимых с обучением под слабой супервизией. Не является ли это ключом к созданию более интуитивных и эффективных систем, способных понимать и взаимодействовать с окружающим миром?
Восприятие и Действие: Основы Аффорданса
Для эффективного взаимодействия с окружающим миром недостаточно просто идентифицировать объекты, необходимо понимать, как их можно использовать — это и есть визуальная доступность, или аффорданс. Данное понятие выходит за рамки простого распознавания формы и материала; оно подразумевает неявное понимание возможностей, которые объект предоставляет для действий. Например, ручка не просто цилиндрический предмет, а инструмент для письма, а дверная ручка — приглашение к открытию. Восприятие аффорданса — это сложный процесс, включающий анализ визуальной информации и соотнесение её с предыдущим опытом и целями действующего субъекта, позволяющий предвидеть результаты взаимодействия и выбирать наиболее подходящие действия.
Восприятие окружающего мира и возможность эффективного взаимодействия с ним неразрывно связаны с точным геометрическим восприятием объектов. Для определения способов использования предмета необходимо, прежде всего, распознавать его составные части и пространственное расположение этих частей. Именно способность точно оценивать форму, размер и ориентацию объектов в пространстве позволяет мозгу моделировать потенциальные действия с ними. Например, для поднятия чашки важно определить ее ручку и центр тяжести, а для прохождения через дверной проем — оценить ширину проема и собственные габариты. Таким образом, точное геометрическое восприятие является фундаментом для понимания того, как объект может быть использован, и служит основой для планирования целенаправленных действий.
Восприятие доступности объектов не ограничивается лишь зрительным определением их формы и свойств; успешное взаимодействие с миром требует моделирования того, как агент активно взаимодействует с этими объектами и их структурой. Именно эта способность — “восприятие взаимодействия” — позволяет предсказывать возможные действия и выбирать наиболее подходящий способ использования предмета. Исследования показывают, что мозг не просто регистрирует визуальную информацию, но и создает внутреннюю модель, отражающую динамику взаимодействия, учитывающую физические свойства объекта, возможности манипулирования и потенциальные последствия действий. Эта сложная система позволяет человеку, например, интуитивно понять, как открыть дверь, поднять чашку или использовать инструмент, даже если он никогда раньше не сталкивался с подобной ситуацией.
Методы Обучения: Спектр Подходов к Аффордансу
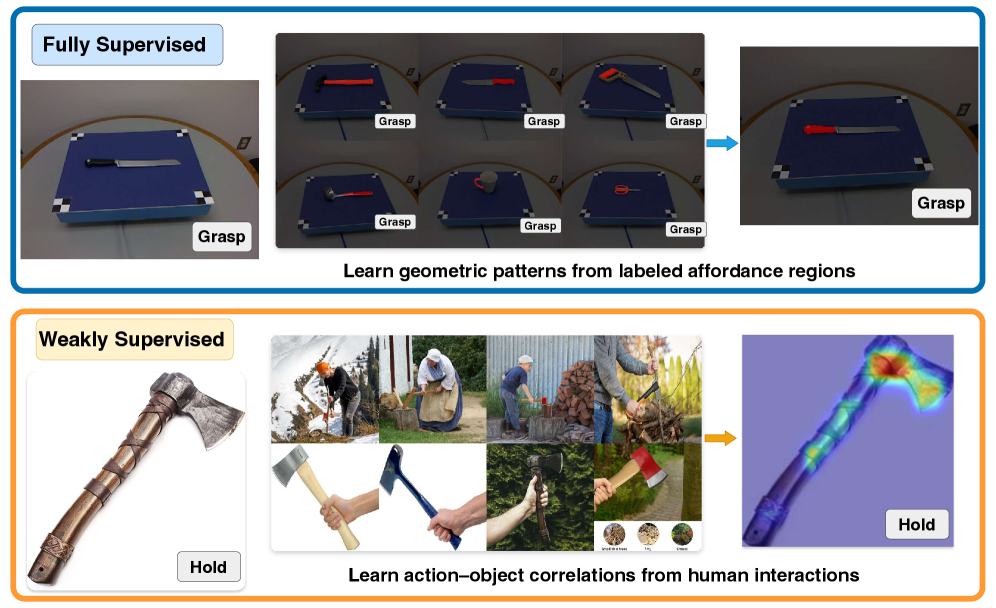
Традиционные методы обучения с полным контролем обеспечивают точное предсказание аффордансов, однако требуют обширных и трудоемких аннотаций на уровне пикселей. Для обучения моделей необходимо вручную размечать каждый пиксель изображения, указывая, какие объекты и действия с ними присутствуют. Этот процесс является ресурсоемким как по времени, так и по человеческим ресурсам, поскольку требует высокой точности и последовательности в аннотациях. Объем необходимых данных для достижения высокой производительности модели часто экспоненциально увеличивается с ростом сложности сцены и разнообразия объектов, что делает масштабирование таких систем проблематичным.
В отличие от методов с полным обучением, требующих трудоемкой разметки на уровне пикселей, слабоконтролируемые методы обеспечивают более масштабируемое решение для определения аффордансов. Они используют косвенные поведенческие сигналы, такие как взаимодействия человека с объектами, для вывода функциональных возможностей объекта. Например, наблюдение за тем, как человек берет в руки кружку, позволяет сделать вывод о ее возможности быть использованной для питья. Этот подход позволяет значительно снизить затраты на разметку данных, поскольку не требуется детальной аннотации изображений, а достаточно анализа действий, связанных с объектом.
Недавняя тенденция в распознавании аффордансов использует методы открытой лексики, опирающиеся на семантические ассоциации, полученные в процессе предварительного обучения на масштабных датасетах изображений и текста. Данный подход позволяет обобщить процесс распознавания аффордансов, используя знания, извлеченные из широкого спектра визуальных и текстовых данных. В отличие от методов, требующих размеченных данных, методы открытой лексики способны идентифицировать аффордансы для объектов, не встречавшихся в процессе обучения, благодаря использованию семантических связей между объектами и возможными действиями над ними, установленных в процессе предварительного обучения больших языковых моделей. Это достигается путем сопоставления визуальных признаков объекта с текстовыми описаниями действий, которые с ним связаны.
Геометрические Основы: Моделирование Приоритетов Взаимодействия
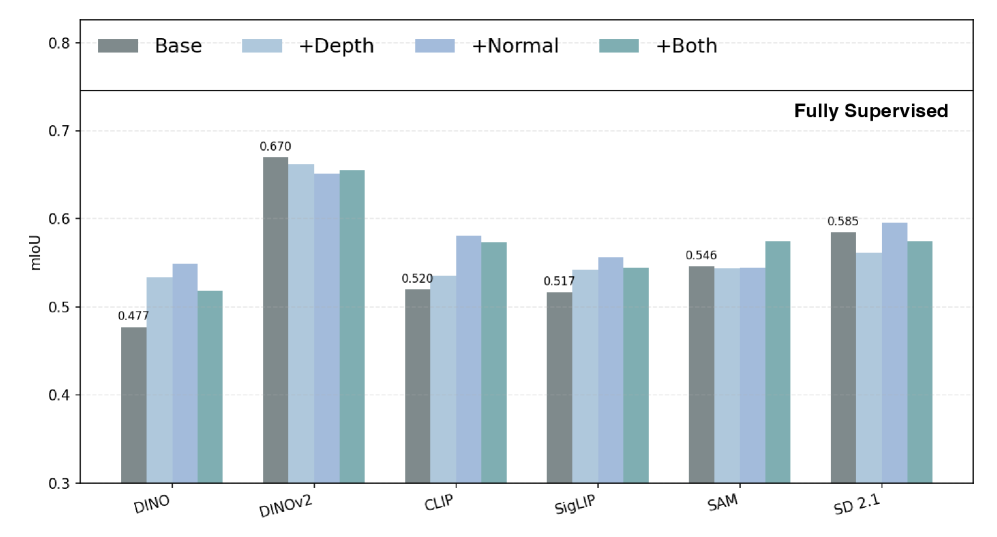
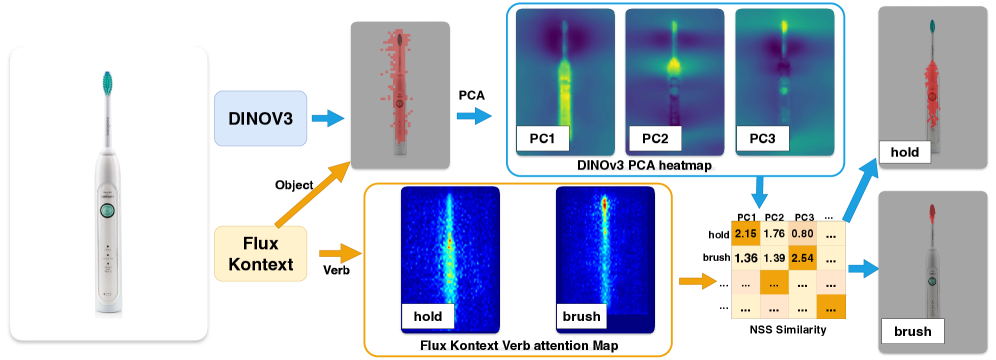
Визуальная модель признаков (VFM) DINOv3 обеспечивает надежную основу для геометрического анализа благодаря своей структуре, демонстрирующей устойчивую организацию на уровне частей объектов. DINOv3, обученная методом самообучения, выделяет значимые визуальные признаки, которые позволяют эффективно сегментировать и понимать отдельные компоненты сложных сцен. Эта организация на уровне частей критически важна для последующего анализа геометрических взаимосвязей между объектами и для определения потенциальных точек взаимодействия. В частности, архитектура DINOv3 способствует формированию представлений, в которых близкие по смыслу части объектов кодируются в близких векторных пространствах, что облегчает их идентификацию и последующее использование в задачах, связанных с пониманием сцены и планированием действий.
Набор данных UMD (UMD Dataset) является ключевым ресурсом для анализа геометрических представлений и валидации сегментации аффордансов. Данный набор содержит изображения различных объектов в различных сценах, аннотированные с указанием геометрических свойств и возможных действий, которые с ними можно совершить. Использование UMD позволяет проводить количественную оценку качества алгоритмов, определяющих геометрическую структуру объектов и предсказывающих их функциональное назначение, а также верифицировать точность сегментации областей, доступных для взаимодействия. Набор данных обеспечивает стандартизированную платформу для сравнительного анализа различных подходов к пониманию геометрии и аффордансов, способствуя развитию более надежных и эффективных систем компьютерного зрения.
Генеративная модель Flux использует механизм внимания, обусловленного глаголами (verb-conditioned attention), реализованный посредством кросс-внимания, для захвата априорных знаний об взаимодействиях и установления связи между глаголами и соответствующими областями объектов. Этот подход позволяет выполнять оценку доступности (affordance estimation) в условиях нулевой настройки (zero-shot) с результатами, сопоставимыми с методами, требующими слабой разметки данных, на наборе данных AGD20K. Кросс-внимание позволяет модели динамически фокусироваться на релевантных частях изображения, исходя из заданного глагола, тем самым улучшая точность определения возможных действий с объектами.
Объединение геометрического и перцептивного восприятия взаимодействия позволило добиться значительного снижения расхождения Кульбака-Лейблера (KLD). Снижение KLD указывает на повышение уверенности и чёткости предсказаний модели. Более низкое значение KLD свидетельствует о том, что распределение вероятностей, предсказанное моделью, ближе к истинному распределению, что приводит к более точным и надёжным результатам при оценке аффордансов и планировании действий. Данный показатель является ключевым для оценки качества вероятностных моделей и подтверждает эффективность предложенного подхода к слиянию различных источников информации.
Результаты экспериментов демонстрируют улучшение метрики Similarity (SIM), что свидетельствует о более полном охвате истинного распределения данных и повышении точности модели в прогнозировании действий. Одновременно с этим, наблюдается прирост Normalized Scanpath Saliency (NSS), указывающий на способность модели выделять наиболее релевантные области изображения, непосредственно связанные с возможными действиями. Увеличение значений SIM и NSS подтверждает эффективность предложенного подхода в улучшении как точности, так и полноты предсказаний, а также в фокусировке внимания на ключевых областях изображения, важных для определения аффордансов.
Исследование демонстрирует, что понимание визуальной доступности требует не только геометрического восприятия объектов, но и осознания способов взаимодействия с ними. Этот подход, основанный на извлечении существующих возможностей из визуальных фундаментальных моделей, позволяет добиться значительных результатов в обучении без учителя. Как заметила Фэй-Фэй Ли: «Искусственный интеллект должен быть ориентирован на человека, а не наоборот». Эта фраза отражает суть представленной работы — создание систем, которые способны понимать мир так, как это делает человек, учитывая как форму, так и функциональность объектов и возможность их использования. Подчеркивается важность взаимодействия между геометрическим восприятием и пониманием способов взаимодействия, что является ключевым для создания интуитивно понятных и эффективных систем искусственного интеллекта.
Куда же дальше?
Представленная работа, подобно тонкой настройке инструмента, обнажает скрытые возможности существующих моделей. Однако, эхо этой мелодии не должно усыпить бдительность. Истинное понимание аффордансов — не просто распознавание геометрии и потенциальных взаимодействий, но и предчувствие намерений, контекста, и даже… неловкости. Модели пока лишь имитируют понимание, подобно умелому пианисту, воспроизводящему ноты, не чувствуя их душу.
Следующим шагом представляется не столько наращивание вычислительных мощностей, сколько углубление в природу репрезентаций. Как заставить модель не просто «видеть» рукоятку двери, но и «понимать», что она предназначена для открытия, а не для игры в барабан? Необходимо исследовать, как знания о физическом мире, здравый смысл и даже интуиция могут быть вплетены в структуру этих моделей, чтобы они перестали быть просто статистическими оракулами.
В конечном итоге, задача заключается не в создании идеального алгоритма, а в построении системы, которая способна к обучению на ошибках, адаптации к новым ситуациям и, возможно, даже к проявлению некоторой доли творческого подхода. В противном случае, все эти сложные вычисления останутся лишь красивой, но пустой симфонией.
Оригинал статьи: https://arxiv.org/pdf/2602.20501.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Lenovo Legion Y70 (2026) ОБЗОР: скоростная зарядка, чёткое изображение, много памяти
- Лучшие смартфоны. Что купить в июне 2026.
- vivo iQOO 15T ОБЗОР: огромный накопитель, яркий экран, плавный интерфейс
- Motorola Moto G47 ОБЗОР: удобный сенсор отпечатков, плавный интерфейс, большой аккумулятор
- Honor Play 80 Pro ОБЗОР: плавный интерфейс, большой аккумулятор, удобный сенсор отпечатков
- Что купить фотографу. Рекомендации
- Honor Magic8 RSR Porsche Design ОБЗОР: замедленная съёмка видео, беспроводная зарядка, чёткое изображение
- Фотографируем муравьёв с Андреем Павловым
- Обзор объектива Tokina 11-16mm f/2.8 AF
- Blackview Oscal Tiger 12 ОБЗОР: большой аккумулятор, плавный интерфейс, быстрый сенсор отпечатков
2026-02-25 11:02