Виртуальный помощник в родах: новая система обучения для будущих врачей
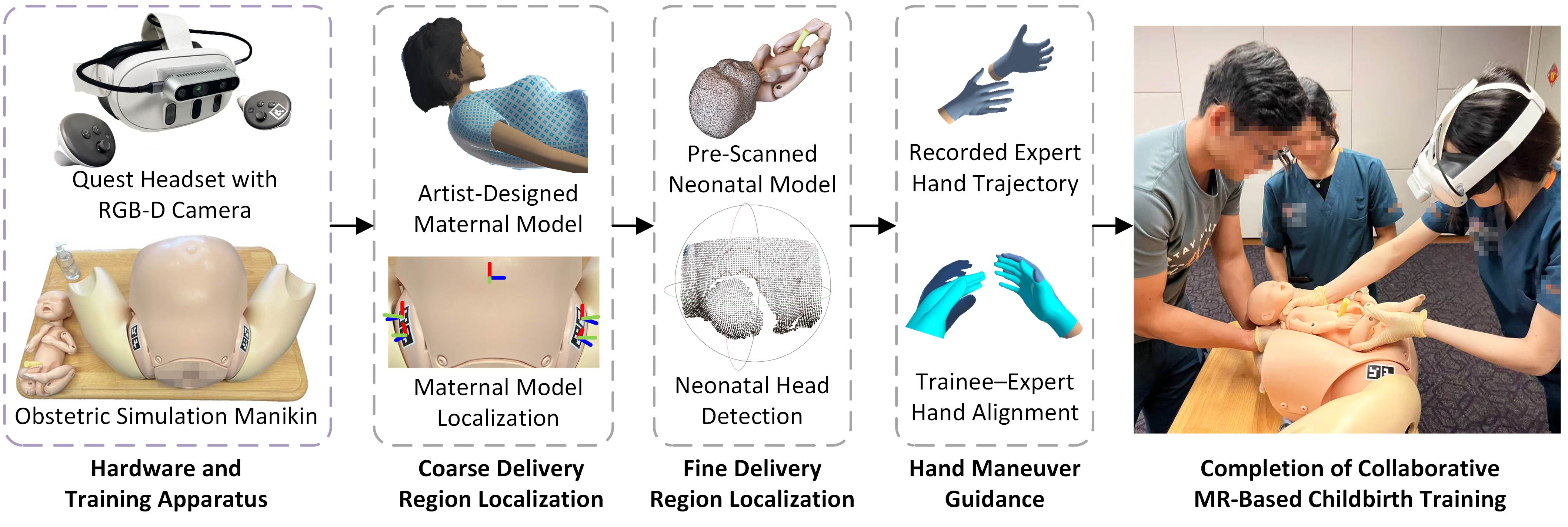
Исследователи разработали смешанную реальность, объединяющую виртуальные подсказки с тактильным взаимодействием с манекеном, для повышения эффективности обучения родовспоможению.
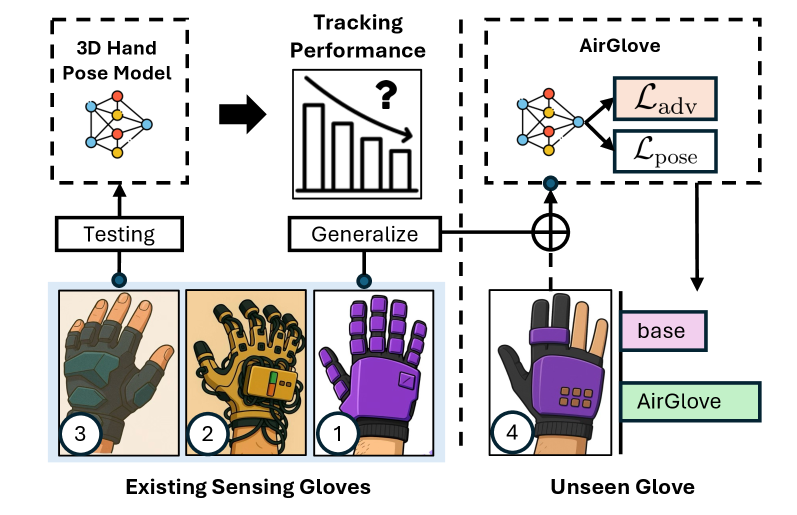
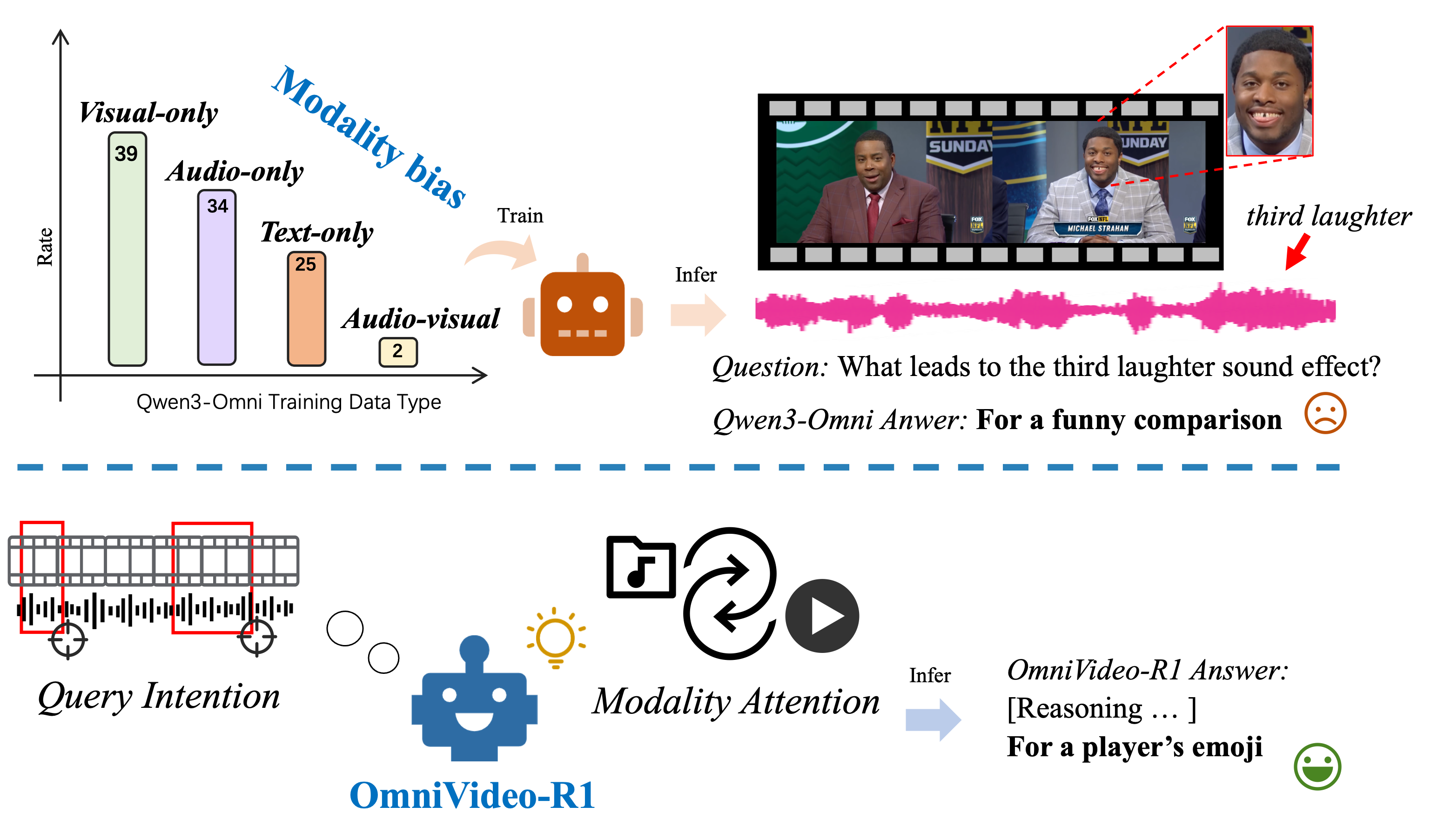
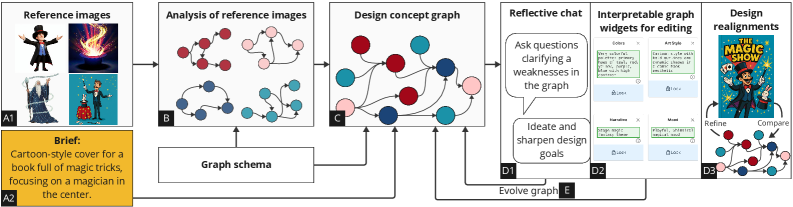
![Траектории семантического поиска, формируемые кумулятивными списками слов, анализируются с использованием динамических метрик, таких как скорость, ускорение и энтропия [latex] x^{\prime} [/latex], [latex] x^{\prime\prime} [/latex], для последующей оценки дисперсии этих траекторий вокруг общего центроида, что позволяет выявить закономерности в организации семантического пространства.](https://arxiv.org/html/2602.05971v1/figures/pipeline.png)
