Адаптация ИИ к Разным Пользователям: Новый Подход к Управлению Мозгом
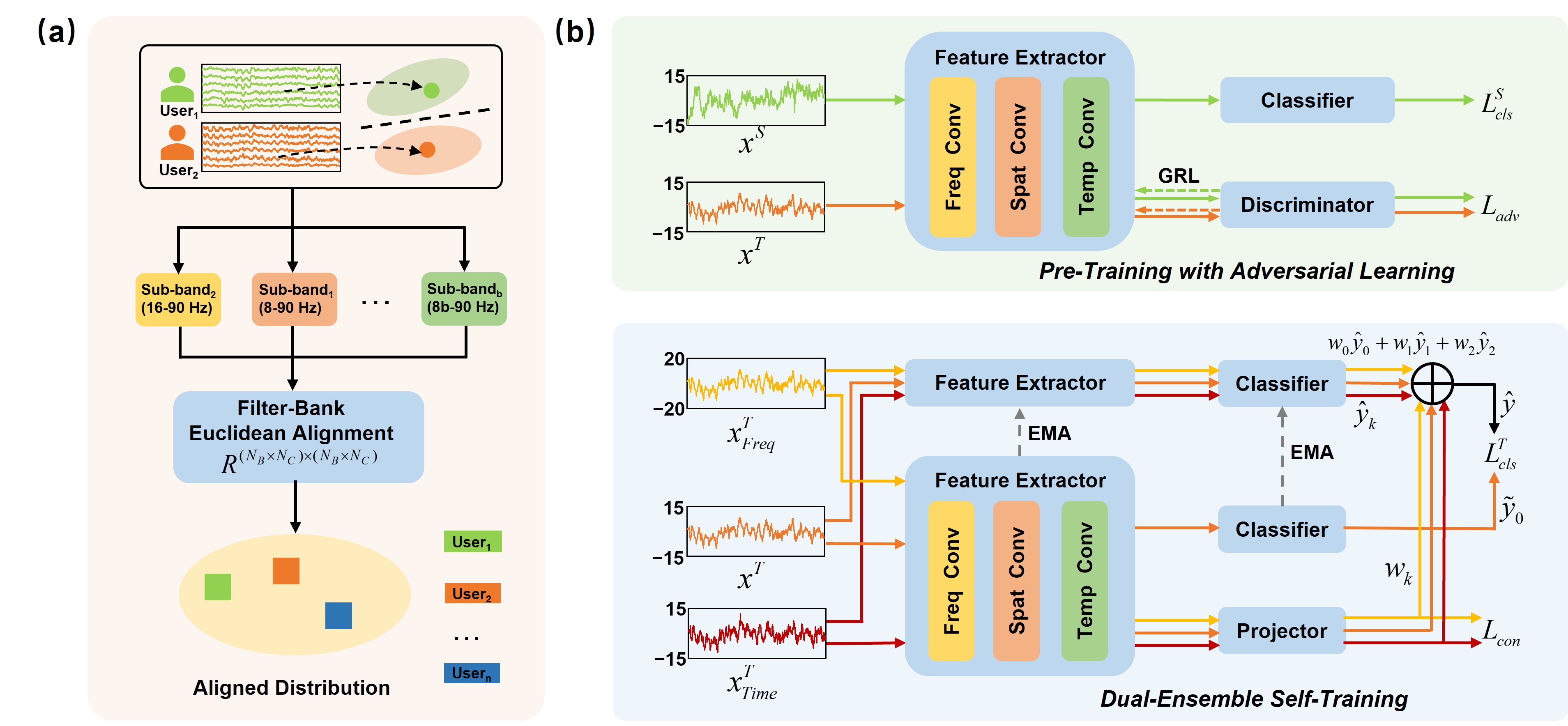
Исследователи предлагают инновационный метод адаптации алгоритмов к индивидуальным особенностям мозга, значительно повышая точность систем управления на основе ЭЭГ.
Исследователи предлагают инновационный метод адаптации алгоритмов к индивидуальным особенностям мозга, значительно повышая точность систем управления на основе ЭЭГ.

Новая платформа AIR-VLA объединяет возможности компьютерного зрения, обработки естественного языка и управления роботами для выполнения сложных задач в воздухе.
Новое исследование показывает, что современные модели, связывающие зрение и язык, часто полагаются на заученные паттерны, а не на истинное визуальное восприятие.
![Архитектура предполагает предварительную обработку позиционного сигнала для получения сигнала скорости, который затем подается на Pre-activation DenseNet, где каждый сверточный слой имеет ядро размером [latex]k=3[/latex], шаг [latex]s=1[/latex] и изменяющийся коэффициент дилатации [latex]d[/latex]; последующий регрессионный блок использует выход DenseNet для предсказания оценок объекта, определяемых количеством предсказанных оценок [latex]NN[/latex].](https://arxiv.org/html/2601.21045v1/x1.png)
Новое исследование показывает, как глубокое обучение может анализировать движения глаз, чтобы оценить уровень усталости и когнитивную нагрузку пользователя, но межсубъектная обобщаемость остается сложной задачей.

Новое исследование показывает, как визуальные характеристики веб-страниц влияют на решения, принимаемые интеллектуальными агентами при поиске информации.
Новая система сочетает искусственный интеллект и исторические изображения, чтобы стимулировать личные воспоминания и сохранять культурное наследие для людей с когнитивными нарушениями.

Новое исследование выявляет слабые места современных моделей преобразования текста в изображения в понимании и воспроизведении сложных пространственных взаимосвязей.

Новая система AnthropoCam позволяет преображать изображения, отражая эстетику эпохи влияния человека, прямо на вашем смартфоне.
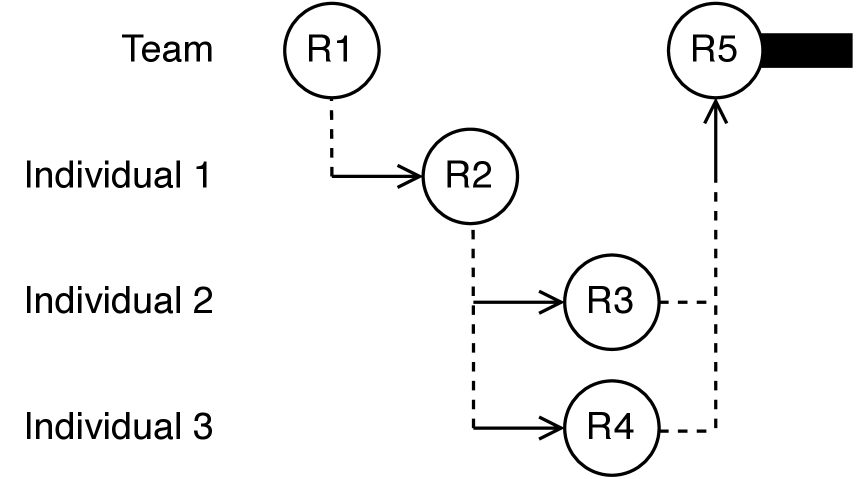
Исследование показывает, как смешанные команды, включающие людей с разными визуальными способностями, адаптируют информацию для совместной работы, выявляя скрытые механизмы координации.
![Модель обрабатывает визуальную информацию, включая изображения и видеопоследовательности, совместно со сложными лингвистическими инструкциями, посредством кодировщика визуальных данных и адаптера, после чего все входные токены объединяются и поступают в декодер [latex]Thinker[/latex], обеспечивая комплексное понимание и генерацию ответа.](https://arxiv.org/html/2601.21199v1/images/workflow.png)
Исследователи представили Thinker — масштабную модель, объединяющую зрение и язык для управления роботами и понимания окружающего мира.